Microsoft Fabric Architectuur: Een Complete Deep Dive
Microsoft Fabric is het meest ambitieuze dataplatform dat Microsoft ooit heeft gelanceerd. In één geïntegreerde SaaS-omgeving combineert het data-integratie, data engineering, data warehousing, real-time analytics, data science en business intelligence. In dit artikel duiken we diep in de architectuur van Microsoft Fabric: wat zijn de kerncomponenten, hoe werkt OneLake, wat is het verschil tussen Lakehouse en Warehouse, hoe verhoudt Real-Time Analytics zich tot de rest, en hoe past Power BI in het geheel?
Wat is Microsoft Fabric?
Microsoft Fabric werd in mei 2023 aangekondigd op Microsoft Build en is sindsdien in rap tempo uitgegroeid tot een volwassen dataplatform. Het is gebouwd op Azure, maar gepresenteerd als een alles-in-één SaaS-dienst die via één abonnement beschikbaar is: de Fabric-capaciteit.
De kerngedachte achter Fabric is het elimineren van silo’s. Voorheen moest je Azure Data Factory, Azure Synapse Analytics, Azure Data Lake Storage, Azure Databricks, Azure Machine Learning en Power BI apart inrichten en koppelen. Met Fabric zitten al deze mogelijkheden in één platform, met één unified storage-laag (OneLake) en één governance-model (Microsoft Purview).
De zeven ervaringen in Microsoft Fabric
| Ervaring | Doel | Vergelijkbaar met |
|---|---|---|
| Data Engineering | Notebooks, Spark-jobs, Delta-tabellen maken | Azure Databricks / Synapse Spark |
| Data Factory | Data-integratie en orkestratie via pipelines | Azure Data Factory |
| Data Science | ML-experimenten, modellen trainen en deployen | Azure Machine Learning |
| Data Warehouse | SQL-gebaseerd analytics warehouse | Azure Synapse Analytics |
| Real-Time Analytics | Streaming data analyseren met KQL | Azure Data Explorer (ADX) |
| Power BI | Visualisaties en dashboards | Power BI Premium |
| OneLake | Uniforme opslaglaag voor alle ervaringen | Azure Data Lake Storage Gen2 |
OneLake: De Fundamentele Opslaglaag
OneLake is de meest ingrijpende architecturale keuze in Microsoft Fabric. Het is een enkelvoudige, logische data lake die voor de gehele Fabric-tenant geldt. Stel je OneLake voor als een OneDrive voor data: er is maar één, maar elke workspace heeft zijn eigen sectie erin.
Kenmerken van OneLake
- Delta Parquet als standaard: alle data in OneLake wordt opgeslagen in Delta Parquet-formaat. Dit garandeert ACID-transacties, time travel en efficiënte columnar storage.
- Geen datakopieën: alle Fabric-ervaringen (Spark, SQL, Power BI) lezen direct uit OneLake zonder data te kopiëren — dit heet "virtuele toegang" of shortcutting.
- Shortcuts: je kunt shortcuts maken naar externe opslag zoals Azure Data Lake Storage Gen2, Amazon S3 of Google Cloud Storage. De data blijft waar ze is, maar is beschikbaar in OneLake.
- Geo-replicatie: OneLake ondersteunt replicatie naar meerdere Azure-regio’s voor disaster recovery.
- Governance via Microsoft Purview: data catalogus, lineage en sensitivity labels worden automatisch bijgehouden.
OneLake shortcuts: externe data integreren
-- Voorbeeld: een shortcut maken naar ADLS Gen2 via Fabric REST API
POST https://api.fabric.microsoft.com/v1/workspaces/{workspaceId}/items/{itemId}/shortcuts
{
"path": "externe-data/klantdata",
"name": "klantdata-extern",
"target": {
"type": "AdlsGen2",
"location": "https://mijnopslag.dfs.core.windows.net",
"subpath": "/klantdata/productie"
}
}Met shortcuts kun je meerdere databronnen unified beschikbaar maken zonder data-duplicatie. Dit is cruciaal voor organisaties met bestaande Azure-investeringen die geleidelijk naar Fabric willen migreren.
Fabric Lakehouse: De Kern van Data Engineering
Het Fabric Lakehouse combineert de flexibiliteit van een data lake met de querymogelijkheden van een relationeel warehouse. Het is gebaseerd op het open Delta Lake-formaat en biedt zowel een SQL Endpoint als een Spark-omgeving.
Anatomie van een Fabric Lakehouse
- Files sectie: ongestructureerde opslag voor ruwe bestanden (JSON, CSV, Parquet, afbeeldingen, etc.) — de bronze laag
- Tables sectie: Delta-tabellen die automatisch een SQL Endpoint krijgen — de silver en gold lagen
- SQL Endpoint: automatisch gegenereerd read-only SQL-eindpunt waarmee Power BI en andere SQL-tools direct op de tabellen kunnen werken
- Notebooks: PySpark-, Scala- of Spark SQL-notebooks voor data-engineering werkzaamheden
Medallion architectuur in Fabric
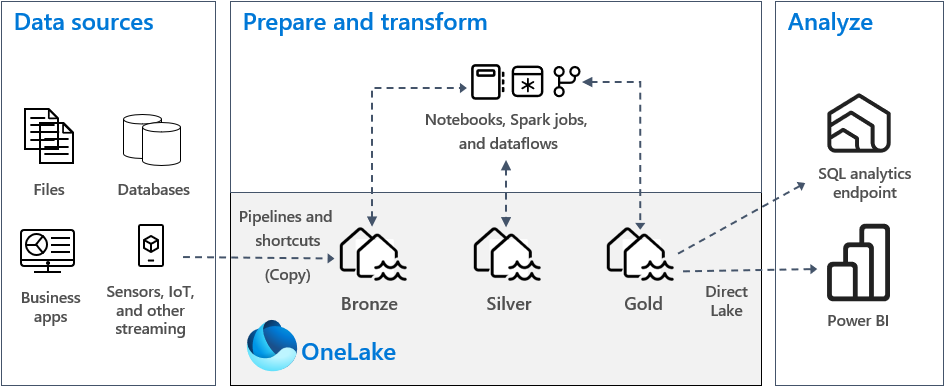
De aanbevolen aanpak voor Fabric is de medallion-architectuur met drie lagen:
| Laag | Lakehouse | Inhoud | Schrijftechniek |
|---|---|---|---|
| Bronze | LH_Bronze | Ruwe brondata, ongewijzigd | Fabric Pipelines (Copy activity) |
| Silver | LH_Silver | Opgeschoonde Delta-tabellen | PySpark Notebooks of dbt |
| Gold | LH_Gold of Warehouse | Rapportage-klare aggregaties | PySpark, SQL of Dataflows Gen2 |
Een praktijkvoorbeeld van een silver-laag transformatie in een Fabric Notebook:
# Fabric Notebook - Silver laag transformatie
from pyspark.sql.functions import col, trim, upper, current_timestamp, lit
from delta.tables import DeltaTable
# Lees uit bronze lakehouse
df_bronze = spark.read.format("delta").load(
"abfss://LH_Bronze@onelake.dfs.fabric.microsoft.com/"
"werkruimte-id/klanten/Files/ruwe-klanten"
)
# Transformaties
df_silver = df_bronze \
.withColumn("naam", trim(col("naam"))) \
.withColumn("postcode", upper(trim(col("postcode")))) \
.withColumn("email", trim(col("email").lower())) \
.filter(col("email").rlike(r"^[^@]+@[^@]+\.[^@]+$")) \
.dropDuplicates(["klant_bron_id"]) \
.withColumn("_verwerkt_op", current_timestamp()) \
.withColumn("_bron", lit("CRM-systeem"))
# Upsert naar silver tabel via MERGE
silver_pad = "Tables/dim_klanten"
if DeltaTable.isDeltaTable(spark, silver_pad):
delta_tabel = DeltaTable.forPath(spark, silver_pad)
delta_tabel.alias("huidig").merge(
df_silver.alias("nieuw"),
"huidig.klant_bron_id = nieuw.klant_bron_id"
).whenMatchedUpdateAll() \
.whenNotMatchedInsertAll() \
.execute()
else:
df_silver.write.format("delta").mode("overwrite").save(silver_pad)
print(f"Silver tabel bijgewerkt: {df_silver.count()} rijen")Fabric Data Warehouse: SQL-First Analytics
Naast het Lakehouse biedt Fabric een volwaardig SQL Data Warehouse. Het grote verschil: het Warehouse is volledig SQL-gebaseerd (geen Spark), terwijl het Lakehouse primair Spark gebruikt met een SQL Endpoint als aanvulling.
Wanneer gebruik je Warehouse vs. Lakehouse?
| Criterium | Fabric Warehouse | Fabric Lakehouse |
|---|---|---|
| Primaire taal | T-SQL (volledig) | PySpark / Spark SQL |
| Write-toegang | Via SQL DML (INSERT, UPDATE, DELETE) | Via Spark of Dataflows |
| Transacties | Volledig ACID via T-SQL | ACID via Delta Lake |
| Doelgroep | SQL-developers, DBA’s | Data engineers, Python-developers |
| Best voor | Rapportagelaag, gold-tabellen | Ruwe data, transformaties, ML |
-- Voorbeeld Fabric Warehouse: stored procedure voor gold laag
CREATE PROCEDURE gold.bereken_maandelijkse_omzet
AS
BEGIN
TRUNCATE TABLE gold.feit_omzet_maand;
INSERT INTO gold.feit_omzet_maand (
jaar,
maand,
product_categorie,
totaal_omzet,
aantal_transacties,
gem_orderwaarde
)
SELECT
YEAR(o.besteldatum) AS jaar,
MONTH(o.besteldatum) AS maand,
p.categorie AS product_categorie,
SUM(r.totaalprijs) AS totaal_omzet,
COUNT(DISTINCT o.order_id) AS aantal_transacties,
AVG(r.totaalprijs) AS gem_orderwaarde
FROM silver.feit_orders o
JOIN silver.bestelregels r ON o.order_id = r.order_id
JOIN silver.dim_producten p ON r.product_id = p.product_id
WHERE o.status = ‘Afgerond’
GROUP BY YEAR(o.besteldatum), MONTH(o.besteldatum), p.categorie;
PRINT ‘Gold laag bijgewerkt: ‘ + CAST(@@ROWCOUNT AS VARCHAR) + ‘ rijen’;
END;Real-Time Analytics: Eventstream en KQL Database
Real-Time Analytics in Fabric is gebaseerd op Azure Data Explorer (ADX) technologie en is ontworpen voor het opnemen en analyseren van hoge volumes event- en telemetriedata. De twee kerncomponenten zijn Eventstream en de KQL Database (Kusto Query Language).
Eventstream
Eventstream is de no-code/low-code manier om streamingdata op te nemen in Fabric. Verbindingen zijn beschikbaar met:
- Azure Event Hubs
- Azure IoT Hub
- Kafka (on-premises of cloud)
- Custom API-endpoints
- Azure Service Bus
Vanuit Eventstream kun je data routeren naar een KQL Database, een Lakehouse of een Warehouse — of naar meerdere bestemmingen tegelijk.
KQL Database en queries
De Kusto Query Language (KQL) is een krachtige querytaal geoptimaliseerd voor tijdreeksdata en telemetrie. De syntax lijkt op SQL maar is meer functioneel van aard:
// KQL voorbeeld: temperatuurpieken detecteren
WeatherEvents
| where ingestion_time() > ago(24h) // Laatste 24 uur
| where temperatuur_celsius > 30 // Hittegolf filter
| summarize
max_temp = max(temperatuur_celsius),
avg_temp = avg(temperatuur_celsius),
aantal = count()
by bin(timestamp, 1h), stad // Per uur aggregeren
| order by timestamp desc, max_temp desc
| project timestamp, stad, max_temp, avg_temp, aantal
// Real-time anomaliedetectie met series_decompose_anomalies()
WeatherEvents
| make-series gem_temp = avg(temperatuur_celsius)
on timestamp from ago(7d) to now() step 1h
by stad
| extend anomalies = series_decompose_anomalies(gem_temp)
| mv-expand timestamp, gem_temp, anomalies
| where anomalies != 0
| project timestamp, stad, gem_temp, anomaliesFabric Pipelines: Orkestratie en Data-integratie
Fabric Pipelines zijn de directe opvolger van Azure Data Factory pipelines. Ze bieden een visuele, low-code manier om datapipelines te bouwen met meer dan 100 connectoren voor externe systemen.
Opbouw van een Fabric Pipeline
- Copy Activity: data kopiëren van bron naar bestemming (meest gebruikte activiteit)
- Notebook Activity: een PySpark-notebook uitvoeren als onderdeel van een pipeline
- Dataflow Gen2 Activity: een Power Query-gebaseerde dataflow starten
- Stored Procedure Activity: een SQL stored procedure aanroepen in een Warehouse
- Lookup / Get Metadata: data ophalen om beslissingen te maken in de pipeline
- If/Switch/ForEach: controleflow voor conditionele logica en iteraties
// Fabric Pipeline JSON-definitie voor een dagelijkse bronze-naar-silver pipeline
{
"name": "PLN_Bronze_To_Silver_Daily",
"properties": {
"activities": [
{
"name": "ACT_Copy_Orders_Bronze",
"type": "Copy",
"source": {
"type": "SqlSource",
"sqlReaderQuery": "SELECT * FROM orders WHERE modified_date >= ‘@{addDays(utcnow(), -1)}’"
},
"sink": {
"type": "LakehouseTableSink",
"tableActionOption": "Append"
}
},
{
"name": "ACT_Transform_Silver",
"type": "SparkJob",
"dependsOn": [{"activity": "ACT_Copy_Orders_Bronze", "dependencyConditions": ["Succeeded"]}],
"notebook": "/Shared/Notebooks/transform_orders_silver"
}
],
"triggers": [
{
"type": "ScheduleTrigger",
"recurrence": {"frequency": "Day", "interval": 1, "startTime": "2025-01-01T02:00:00Z"}
}
]
}
}Power BI in Fabric: Directe Semantic Model Integratie
Power BI is diep geïntegreerd in het Fabric-ecosysteem. In tegenstelling tot de traditionele setup — Power BI verbindt via een gateway naar een datasource — leest Power BI in Fabric direct uit OneLake via het SQL Endpoint van een Lakehouse of Warehouse.
Direct Lake modus: de doorbraak
De grootste innovatie voor Power BI in Fabric is de Direct Lake connectiemodus. Dit is een fundamenteel nieuwe benadering naast de bestaande Import en DirectQuery modi:
| Modus | Hoe het werkt | Voordeel | Nadeel |
|---|---|---|---|
| Import | Data wordt gekopieerd in het semantic model | Snelste queries | Data is niet real-time; refresh nodig |
| DirectQuery | Elke query gaat naar de database | Altijd actueel | Trager, hoge druk op bron |
| Direct Lake | Leest Delta-bestanden direct uit OneLake | Import-snelheid + real-time data | Alleen beschikbaar in Fabric |
Direct Lake werkt door de Delta Parquet-bestanden in OneLake direct in het geheugen van de Vertipaq-engine te laden, zonder tussenliggende opslag of kopiëren. Zodra een Delta-tabel wordt bijgewerkt, detecteert Direct Lake de wijziging automatisch en refresht alleen de gewijzigde partities.
Power BI Semantic Model met Direct Lake
// TMDL (Tabular Model Definition Language) - semantic model definitie
table DimKlant
lineageTag: dim-klant-001
column KlantId
dataType: int64
isHidden: true
lineageTag: klant-id
column Naam
dataType: string
lineageTag: klant-naam
column Stad
dataType: string
lineageTag: klant-stad
partition DimKlant-fabricPartitie
mode: directLake // Direct Lake modus
source: dim_klanten // Verwijst naar Lakehouse-tabel
// DAX maatstaf
measure [Totale Omzet] =
SUMX(
RELATEDTABLE(FeitVerkopen),
[Verkoopbedrag]
)
FORMAT "#,##0.00 €"Fabric Architectuur: Alles Samengebracht
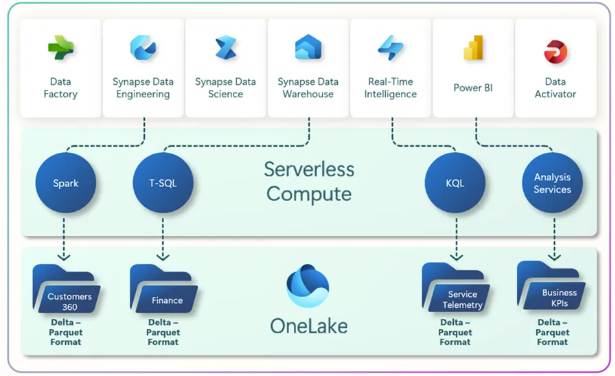
Een typische productie-architectuur in Microsoft Fabric ziet er als volgt uit:
- Bronnen — ERP-systemen, CRM, REST APIs, IoT-sensoren, externe datafeeds
- Opname — Fabric Pipelines (batch) of Eventstream (streaming) brengen data naar OneLake
- Bronze Lakehouse — ruwe data in Delta-formaat, partitioneerd op opnamedatum
- Silver Lakehouse — getransformeerde, opgeschoonde data via PySpark Notebooks of dbt-Core (op Fabric)
- Gold Lakehouse / Warehouse — aggregaties en business-logica, klaar voor rapportage
- Semantic Models (Direct Lake) — Power BI leest direct uit Gold via Direct Lake
- Dashboards en rapporten — Power BI rapporten beschikbaar via Fabric-apps of geëmbed in Microsoft Teams
Governance en Beveiliging in Fabric
Fabric heeft governance ingebakken via Microsoft Purview en de Fabric-tenant-instellingen. Belangrijke governance-concepten:
- Workspaces: de basiseenheid voor toegangsbeheer. Rollen zijn Admin, Member, Contributor en Viewer.
- Domains: een logische groepering van workspaces per businessdomein (bijv. Finance, Sales, HR)
- Data Access Control: rijniveau- en kolomniveaubeveiliging in Warehouse en Lakehouse SQL Endpoint
- Sensitivity Labels: Microsoft Purview sensitivity labels worden doorgegeven van databron tot Power BI-rapport
- Data Lineage: automatisch bijgehouden via Microsoft Purview — zie exact welk rapport afhankelijk is van welke tabel in welk Lakehouse
Kosten en Licenties
Fabric werkt met Fabric-capaciteiten, vergelijkbaar met Power BI Premium-capaciteiten. De capaciteit wordt gemeten in Capacity Units (CU):
| SKU | CU | Maandprijs (indicatief) | Geschikt voor |
|---|---|---|---|
| F2 | 2 CU | ~€250/maand | Ontwikkeling, proof-of-concept |
| F4 | 4 CU | ~€500/maand | Klein team, beperkte workloads |
| F8 | 8 CU | ~€1.000/maand | Middelgrote organisatie |
| F64 | 64 CU | ~€8.000/maand | Enterprise, grote datasets |
Naast de capaciteitskosten rekent OneLake opslagkosten aan (vergelijkbaar met ADLS Gen2: ~€20/TB/maand). Networking-kosten voor data-egress gelden ook. Voor kleine organisaties is F2 of F4 vaak voldoende om te starten.
Wanneer Kies je voor Microsoft Fabric?
Fabric is bijzonder aantrekkelijk voor organisaties die:
- Al sterk Microsoft-georiënteerd zijn (Azure, Microsoft 365, Power BI)
- Willen consolideren van meerdere losse Azure-diensten naar één platform
- Een team hebben met gemengde skills (SQL-developers én Python-engineers)
- Real-time analytics willen combineren met batch-verwerking
- Governance en data lineage serieus nemen
Fabric is minder geschikt als je al diep geïnvesteerd hebt in Databricks of Snowflake, of als je AWS of GCP gebruikt als primaire cloudprovider.
Conclusie
Microsoft Fabric is een genuanceerd en krachtig platform dat de traditionele silo’s in de datastack doorbreekt. OneLake als unified opslaglaag, Direct Lake voor Power BI, de combinatie van Lakehouse en Warehouse, en de ingebakken real-time analytics maken het tot een volwassen keuze voor organisaties die hun datalandschap willen moderniseren. De architectuur is flexibel genoeg voor kleine proof-of-concepts en robuust genoeg voor enterprise-implementaties. Voor organisaties die diep in het Microsoft-ecosysteem zitten, is Fabric een logische en krachtige stap voorwaarts.