Twee Scholen, Eén Probleem
Elke organisatie die serieus met data werkt, stuit op dezelfde uitdaging: hoe bewaar je de historie van veranderende gegevens? Een klant verhuist, een product krijgt een nieuwe prijs, een medewerker wisselt van afdeling. De data van gisteren is anders dan vandaag — en je wilt beiden bewaren.
Er zijn twee dominante methoden die dit probleem aanpakken, elk met een fundamenteel andere filosofie:
Kimball — SCD
Slowly Changing Dimensions. Historisering binnen de dimensietabel zelf. Focus op business-leesbare stermodellen met feit- en dimensietabellen.
Data Vault — Satellites
Historisering in aparte Satellite-tabellen rondom Hubs en Links. Focus op flexibiliteit, auditeerbaarheid en het scheiden van structuur en context.
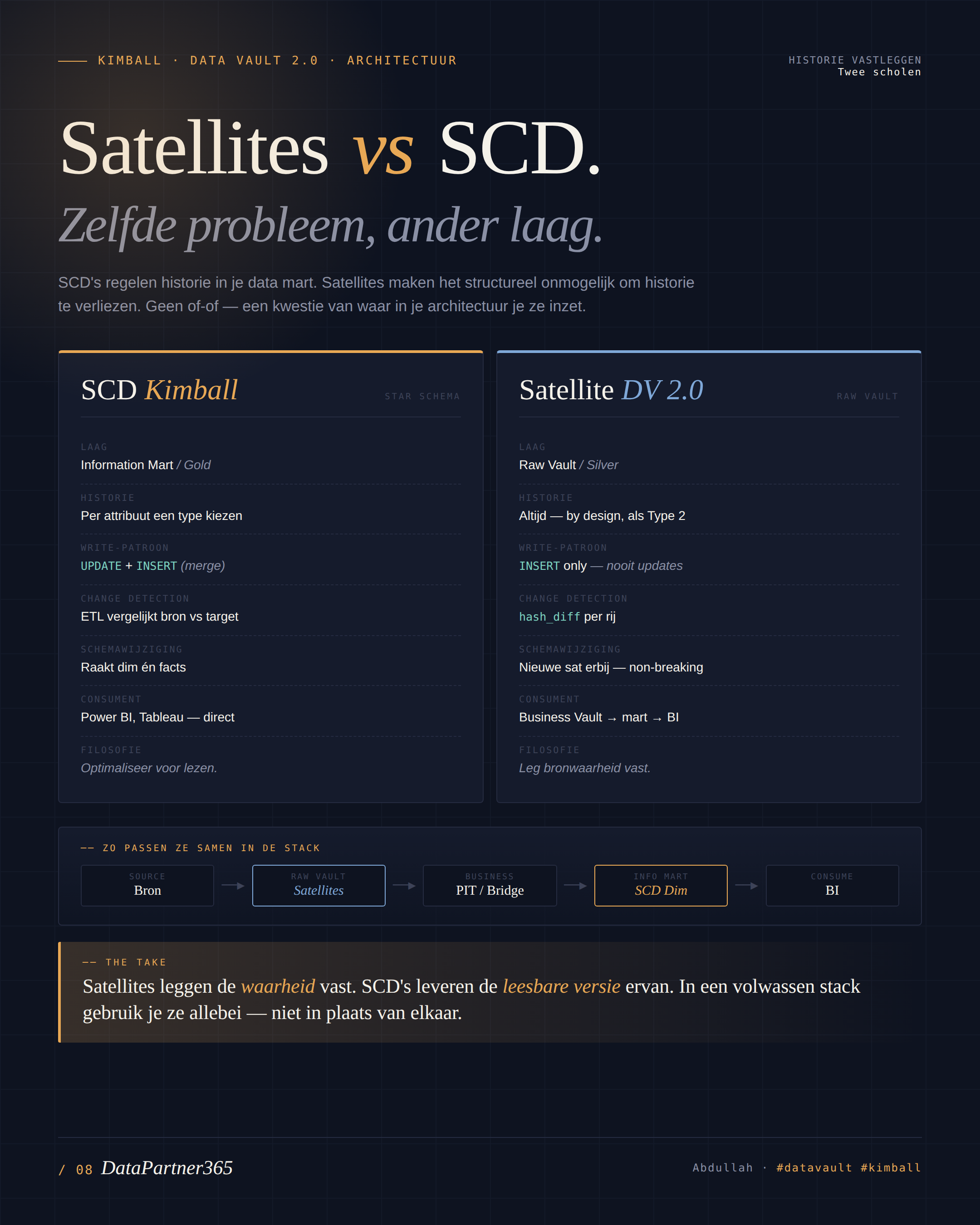
Herhaling: Wat is SCD?
Slowly Changing Dimensions komen uit de Kimball-methodologie en beschrijven hoe je veranderingen in dimensietabellen opslaat. Het meest gebruikte type is SCD Type 2: bij elke wijziging wordt een nieuwe rij aangemaakt met geldigheidsperiodes.
-- SCD Type 2: Klant dimensietabel met historische rijen
SELECT * FROM dim_klant WHERE klant_id = 1001;
| klant_sk | klant_id | naam | stad | geldig_van | geldig_tot | is_actueel |
|----------|----------|---------------|-----------|------------|------------|------------|
| 101 | 1001 | Jan de Vries | Amsterdam | 2024-01-15 | 2026-03-31 | FALSE |
| 102 | 1001 | Jan de Vries | Rotterdam | 2026-04-01 | 9999-12-31 | TRUE |
Alles zit in één tabel: de business key, alle beschrijvende attributen, en de geldigheidsperiodes. De feitentabel verwijst via een surrogate key (klant_sk) naar de juiste versie. Lees voor alle details onze complete gids over de 7 SCD-typen.
Wat zijn Data Vault Satellites?
In Data Vault 2.0 wordt het datamodel opgebouwd uit drie bouwblokken: Hubs, Links en Satellites. De historisering zit volledig in de Satellites.
De drie bouwblokken van Data Vault
- Hub — bevat de unieke business keys (bijv. klant_id). Geen beschrijvende attributen, geen historie. Eén rij per unieke entiteit.
- Link — legt relaties vast tussen Hubs (bijv. klant-bestelling). Geen beschrijvende attributen.
- Satellite — bevat alle beschrijvende attributen en hun volledige historie. Gekoppeld aan een Hub of Link.
-- Hub: alleen de business key
CREATE TABLE hub_klant (
hub_klant_hk CHAR(32) PRIMARY KEY, -- Hash key van klant_id
klant_id INT NOT NULL,
load_date TIMESTAMP NOT NULL,
record_source VARCHAR(50) NOT NULL
);
-- Satellite: beschrijvende attributen + historie
CREATE TABLE sat_klant_adres (
hub_klant_hk CHAR(32) NOT NULL,
load_date TIMESTAMP NOT NULL,
load_end_date TIMESTAMP,
record_source VARCHAR(50),
straat VARCHAR(200),
stad VARCHAR(100),
postcode VARCHAR(10),
land VARCHAR(50),
hash_diff CHAR(32), -- Hash van alle attributen (change detection)
PRIMARY KEY (hub_klant_hk, load_date)
);
-- Aparte satellite voor contactgegevens
CREATE TABLE sat_klant_contact (
hub_klant_hk CHAR(32) NOT NULL,
load_date TIMESTAMP NOT NULL,
load_end_date TIMESTAMP,
record_source VARCHAR(50),
email VARCHAR(200),
telefoon VARCHAR(20),
hash_diff CHAR(32),
PRIMARY KEY (hub_klant_hk, load_date)
);Het kernidee: splitsing van context
Waar SCD alle attributen in één dimensietabel stopt, splitst Data Vault ze op in meerdere Satellites gegroepeerd per bron of per onderwerp. Adresgegevens in de ene Satellite, contactgegevens in een andere, demografische data in weer een andere. Elke Satellite heeft zijn eigen historiseringsritme.
Directe Vergelijking: SCD vs Satellites
| Kenmerk | SCD (Kimball) | Satellites (Data Vault) |
|---|---|---|
| Structuur | Eén brede dimensietabel met alle attributen | Meerdere smalle Satellites per attribuutgroep |
| Historisering | Nieuwe rij per wijziging (Type 2), of overschrijven (Type 1) | Altijd volledige historie, elke Satellite onafhankelijk |
| Granulariteit | Hele dimensierij wordt geversioned bij elke change | Alleen de Satellite met de gewijzigde attributen krijgt een nieuwe rij |
| Bronregistratie | Niet standaard (optioneel) | Verplicht: record_source in elke Satellite |
| Meerdere bronnen | Lastig: welke bron wint bij conflict? | Makkelijk: aparte Satellite per bron |
| Change detection | Vergelijking van individuele kolommen | hash_diff over alle attributen in de Satellite |
| Query-complexiteit | Eenvoudig: feitentabel JOIN dimensie | Complex: Hub JOIN Satellite(s), vaak meerdere joins nodig |
| Tabelgroei | Hoog bij veel attributen (hele rij gedupliceerd) | Efficienter: alleen gewijzigde attribuutgroep groeit |
| Flexibiliteit | Schema-wijzigingen breken bestaande ETL | Nieuwe Satellite toevoegen zonder bestaande structuur aan te passen |
| Leesbaarheid | Hoog: business-vriendelijke stermodellen | Laag: technisch model, business-laag nodig erboven |
Het Granulariteitsprobleem
Het grootste praktische verschil zit in granulariteit van historisering. Stel: een klant heeft 20 attributen verspreid over adres, contact, en demografische data. Bij SCD Type 2 levert elke wijziging — ook als alleen het telefoonnummer verandert — een complete nieuwe rij op met alle 20 attributen gedupliceerd.
Voorbeeld: Impact op Tabelgroei
Een klant wijzigt in 1 jaar: 2x adres, 3x telefoon, 1x email.
| Methode | Nieuwe rijen | Gedupliceerde data |
|---|---|---|
| SCD Type 2 | 6 rijen (1 per wijziging) | Alle 20 attributen gekopieerd per rij |
| Data Vault Satellites | 2 rijen in sat_adres, 3 in sat_contact, 1 in sat_email | Alleen de gewijzigde attribuutgroep |
Bij 10 miljoen klanten wordt dit verschil significant: SCD Type 2 kan 3-5x meer opslagruimte vereisen dan het equivalent in Satellites.
Multi-Source: Waar Data Vault Uitblinkt
In de praktijk komen klantgegevens uit meerdere bronnen: het CRM, de webshop, het ERP-systeem, een extern dataplatform. Bij SCD moet je vooraf beslissen welke bron leidend is (golden record). Bij Data Vault maak je simpelweg een Satellite per bron.
-- Data Vault: aparte Satellite per bron
-- CRM-gegevens
CREATE TABLE sat_klant_crm (
hub_klant_hk CHAR(32),
load_date TIMESTAMP,
record_source VARCHAR(50) DEFAULT 'CRM',
naam VARCHAR(100),
email VARCHAR(200),
segment VARCHAR(50),
hash_diff CHAR(32),
PRIMARY KEY (hub_klant_hk, load_date)
);
-- Webshop-gegevens
CREATE TABLE sat_klant_webshop (
hub_klant_hk CHAR(32),
load_date TIMESTAMP,
record_source VARCHAR(50) DEFAULT 'WEBSHOP',
laatste_login TIMESTAMP,
voorkeurstaal VARCHAR(10),
nieuwsbrief BOOLEAN,
hash_diff CHAR(32),
PRIMARY KEY (hub_klant_hk, load_date)
);
-- Query: combineer beide bronnen voor actuele klantdata
SELECT
h.klant_id,
crm.naam,
crm.email,
crm.segment,
ws.laatste_login,
ws.voorkeurstaal
FROM hub_klant h
JOIN sat_klant_crm crm
ON h.hub_klant_hk = crm.hub_klant_hk
AND crm.load_end_date IS NULL
JOIN sat_klant_webshop ws
ON h.hub_klant_hk = ws.hub_klant_hk
AND ws.load_end_date IS NULL;Voordeel in de praktijk
Als een nieuwe bron wordt aangesloten (bijv. een extern dataverrijkingsplatform), voeg je simpelweg een nieuwe Satellite toe. De Hub, de Links, en alle bestaande Satellites blijven onaangetast. Bij SCD zou je kolommen moeten toevoegen aan de dimensietabel en de ETL-logica aanpassen.
Performance en Query-Patronen
Hier scoort Kimball/SCD traditioneel beter. Een stermodel met SCD Type 2 vereist simpele joins:
-- Kimball: eenvoudige query
SELECT
d.stad,
SUM(f.omzet) AS totale_omzet
FROM feit_orders f
JOIN dim_klant d ON f.klant_sk = d.klant_sk
WHERE d.is_actueel = TRUE
GROUP BY d.stad;Dezelfde query in Data Vault vereist meerdere joins:
-- Data Vault: meerdere joins nodig
SELECT
sa.stad,
SUM(f.omzet) AS totale_omzet
FROM feit_orders f
JOIN hub_klant h ON f.hub_klant_hk = h.hub_klant_hk
JOIN sat_klant_adres sa ON h.hub_klant_hk = sa.hub_klant_hk
AND sa.load_end_date IS NULL
GROUP BY sa.stad;In de praktijk lossen Data Vault-architecturen dit op door een Business Vault of Information Mart laag bovenop het Raw Vault te bouwen. Deze laag bevat gedenormaliseerde views of tabellen die vergelijkbaar zijn met Kimball-dimensies — het beste van beide werelden.
De lagen van een Data Vault architectuur
- Staging — ruwe data uit bronnen, ongewijzigd
- Raw Vault — Hubs, Links, Satellites (historisering)
- Business Vault — afgeleide berekeningen, business rules
- Information Mart — gedenormaliseerde stermodellen voor eindgebruikers (vergelijkbaar met Kimball-dimensies)
Implementatie in Moderne Platforms
dbt: SCD via Snapshots, Data Vault via Packages
-- dbt snapshot voor SCD Type 2 (ingebouwd)
{% snapshot snap_klant %}
{{
config(
target_schema='snapshots',
unique_key='klant_id',
strategy='check',
check_cols=['naam', 'stad', 'email']
)
}}
SELECT * FROM {{ source('crm', 'klanten') }}
{% endsnapshot %}
-- Data Vault via dbt package (dbtvault / automate-dv)
-- pip install dbt-databricks && dbt deps
-- packages.yml:
-- packages:
-- - package: Datavault-UK/automate-dv
-- version: 0.10.xDatabricks: Delta Lake voor beide patronen
Delta Lake's MERGE INTO werkt uitstekend voor zowel SCD als Satellite-loads. Het verschil zit puur in het tabelontwerp, niet in de techniek.
-- Satellite laden in Databricks met MERGE
MERGE INTO sat_klant_adres AS target
USING (
SELECT
md5(cast(klant_id as string)) AS hub_klant_hk,
current_timestamp() AS load_date,
'CRM' AS record_source,
straat, stad, postcode, land,
md5(concat_ws('|', straat, stad, postcode, land)) AS hash_diff
FROM staging_klanten
) AS source
ON target.hub_klant_hk = source.hub_klant_hk
AND target.load_end_date IS NULL
AND target.hash_diff = source.hash_diff
WHEN NOT MATCHED THEN
INSERT (hub_klant_hk, load_date, record_source, straat, stad, postcode, land, hash_diff)
VALUES (source.hub_klant_hk, source.load_date, source.record_source,
source.straat, source.stad, source.postcode, source.land, source.hash_diff);Wanneer Kies Je Wat?
| Kies SCD (Kimball) als... | Kies Data Vault Satellites als... |
|---|---|
| Je team klein is en snelle time-to-value wil | Je meerdere bronnen moet integreren |
| Business users directe toegang tot data nodig hebben | Auditeerbaarheid en traceerbaarheid cruciaal zijn |
| Het datamodel relatief stabiel is | Het datamodel regelmatig verandert of uitbreidt |
| Performance op rapportages de hoogste prioriteit is | Flexibiliteit en schaalbaarheid belangrijker zijn dan query-snelheid |
| Je 1-3 databronnen hebt | Je 5+ databronnen hebt die continu groeien |
| Je BI-tool direct op het warehouse draait | Je een aparte presentatielaag kunt bouwen (Information Mart) |
| MKB met beperkt data engineering team | Enterprise met dedicated data platform team |
De Hybride Aanpak: Het Beste van Beide
In de praktijk kiezen steeds meer organisaties voor een hybride architectuur: Data Vault als integratielaag (Raw Vault) met Kimball-achtige stermodellen als presentatielaag (Information Mart). Dit patroon werkt bijzonder goed met het Medallion Architecture (Bronze-Silver-Gold) principe:
Bronze = Staging
Ruwe data uit alle bronnen, ongewijzigd opgeslagen. Vergelijkbaar met de staging area in Data Vault.
Silver = Raw Vault
Hubs, Links en Satellites. Volledige historisering, bronregistratie, hash-based change detection.
Gold = Information Mart
Kimball-stermodellen met SCD Type 2 dimensies. Geoptimaliseerd voor BI-tools en eindgebruikers.
-- Gold laag: Kimball-dimensie gebouwd vanuit Data Vault
CREATE OR REPLACE VIEW gold.dim_klant AS
SELECT
h.hub_klant_hk AS klant_sk,
h.klant_id,
sa.stad,
sa.postcode,
sc.email,
sc.telefoon,
sa.load_date AS geldig_van,
COALESCE(sa.load_end_date, '9999-12-31') AS geldig_tot,
CASE WHEN sa.load_end_date IS NULL THEN TRUE ELSE FALSE END AS is_actueel
FROM hub_klant h
JOIN sat_klant_adres sa ON h.hub_klant_hk = sa.hub_klant_hk
LEFT JOIN sat_klant_contact sc ON h.hub_klant_hk = sc.hub_klant_hk
AND sc.load_end_date IS NULL;Conclusie
SCD en Data Vault Satellites lossen hetzelfde probleem op — historisering van veranderende data — maar vanuit een fundamenteel ander perspectief. SCD is eenvoudiger en direct bruikbaar voor rapportages. Data Vault is flexibeler en schaalbaarder, maar vereist een extra presentatielaag.
De keuze hangt af van je organisatie:
- Klein team, weinig bronnen, snelle rapportages → Kimball met SCD
- Groot team, veel bronnen, auditverplichtingen → Data Vault met Satellites
- Het beste van beide → Data Vault als integratie + Kimball als presentatie
Ongeacht je keuze: begin met het begrijpen van wat je wilt historiseren en waarom. De techniek volgt vanzelf.
Hulp Nodig bij Implementatie?
Zoek je een Data Engineer of advies over dit onderwerp?